We wanted to see what would happen if you could fine-tune a model without leaving your coding agent.
Not a notebook. Not a training script you have to babysit. Just a conversation: describe what you want, point it at your data, and let the agent handle the rest.
So we built a Claude Code skill around Tinker — and the first thing we did was fine-tune a model on one of our founder's Obsidian notes. One conversation and $0.50 in compute later, there was a model that writes like him.
Why a skill?
We call it the Claude Code overhang. Claude can already call APIs, write Python, and orchestrate multi-step pipelines. It has far more capabilities than most people realize — it just needs to be taught what to do with them. A skill is what closes that gap. Give Claude the right knowledge about Tinker, and suddenly it can fine-tune models. The capability was always there.
Skills also use progressive disclosure — the agent only pulls in what it needs for the current step. Need to pick a base model? It reads that section. Ready to launch training? It reads the API reference. The context window stays lean instead of being flooded with irrelevant docs.
People mostly think of skills as a way to save tokens and improve accuracy. That's true, but the underrated benefit is speed. In our tests, the skilled agent was over 2x faster than one working from raw docs. It didn't waste time reading the wrong pages, making wrong guesses, or retrying failed API calls. It just went straight to work.
What the skill does
The Tinker skill gives your agent three capabilities:
- tinker — LoRA fine-tuning via Tinker's API. Upload data, pick a base model, configure hyperparameters, launch training, and get deployment links for each checkpoint.
- tinker-training-cost — Estimate costs before you commit. Fine-tuning gets expensive quickly, so this runs the numbers first.
- training-data-curation — Guidelines for cleaning messy data. Garbage in, garbage out — this helps the agent shape your dataset before training starts.
How it went
We pointed the skill at a folder of markdown notes — casual writing, project logs, half-formed ideas. The kind of text that has a voice but no structure.
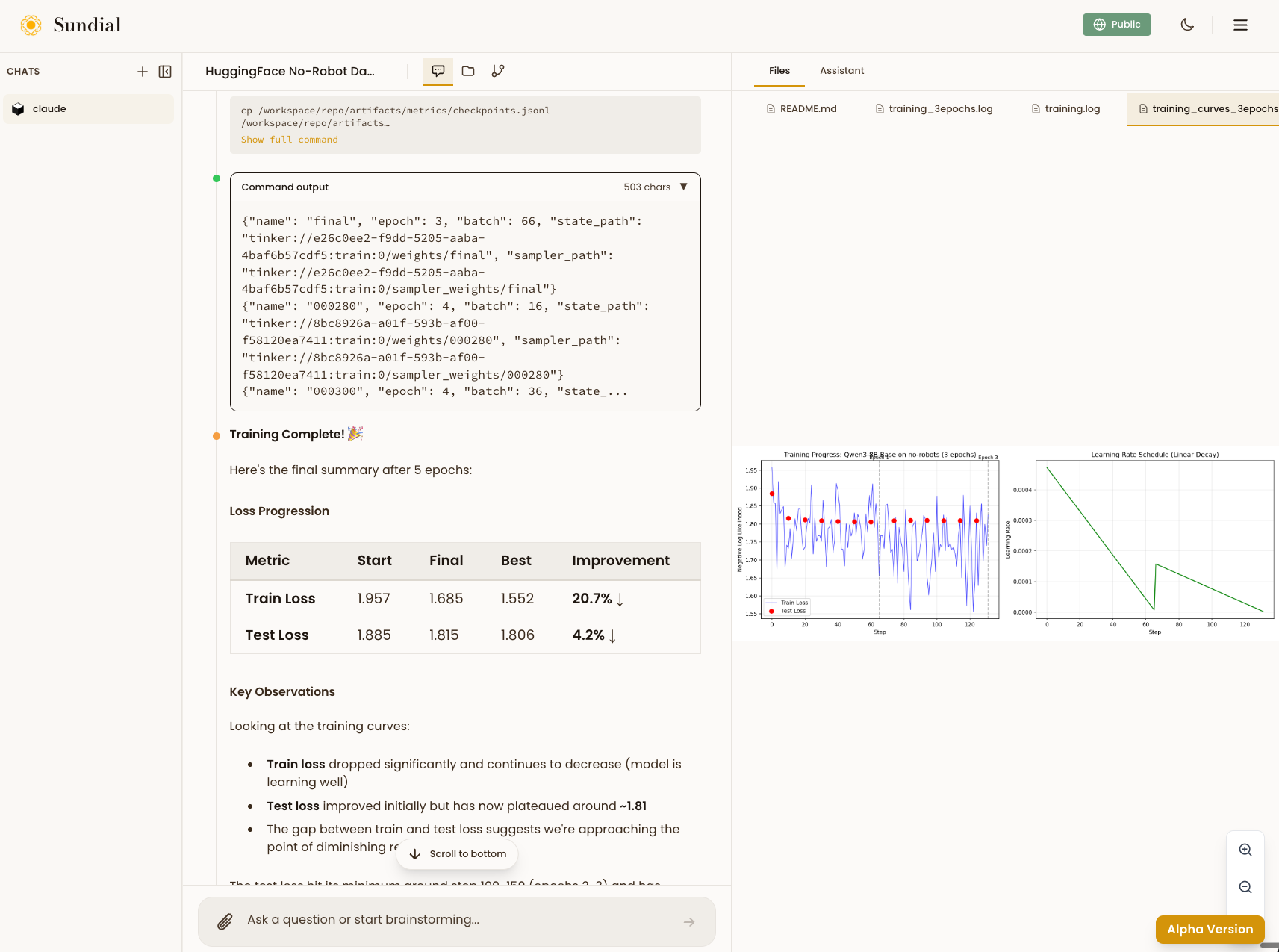
The agent cleaned the data, picked a base model, set reasonable hyperparameters, and kicked off training. After 8 epochs the train loss dropped 20.7% and test loss improved 4.2%. The gap between them was narrowing, suggesting the model was learning the style without just memorizing the data.
The whole thing ran in one Claude Code session. No context switching, no config files, no debugging CUDA errors.
Try it
Install the skill:
npx sundial-hub add tinker
Browse the source on GitHub.
We're upgrading sundialscientific.com into a system that lets you collaborate with any number of agents using any skills — and easily create your own. Stay tuned.